The Batch Mode serves for the sequential processing of multiple data sets. It can be used for fitting with a range of models, Monte Carlo simulations and to aggregate the parameters from existing KM files.
Batch processing is started from the Kinetic menu and opens a dialog window for setting up the batch queue as illustrated below. There are two batch types:
1.Batch based on Macros to sequentially fit models to the data.
2.Batch based on Model Definitions either in the data file itself or via loaded .kmModel definitions. Here a variety of processing types are supported.

Data Files
Two types of data files can be processed:
▪KM files: A .km file saved from PKIN includes a complete definition of the data and the models for the different types of information (blood interpolation model, the tissue model, weighting etc) for each region. Therefore, multiple processing types are supported including coupled fitting and Monte Carlo simulations. Additionally, during fitting, the options on the Extras pane such as parameter initialization and randomized fitting will be effective. A new KM file will be created with the fitting results in the fitting history.
▪Composite .kmData files: A .kmData file contains only the data definition, except for the global specification of a model. Therefore, only the individual tissue model fitting is supported. The result will be saved as a new .km file with the same name as the input file, and with the results in the history.
Use the Add data button for opening a data selection window and select the data sets to be processed from a database or the file system. Further data can incrementally be added, and selected list entries removed.
Starting the Batch
The Run button starts processing, and PMOD will be blocked until processing completes.
Batch Results
The New file and the Append to file buttons can be used to specify a .kinPar file as a container for saving the result parameters of the batch run. These results can be transferred to the R console for performing statistics.
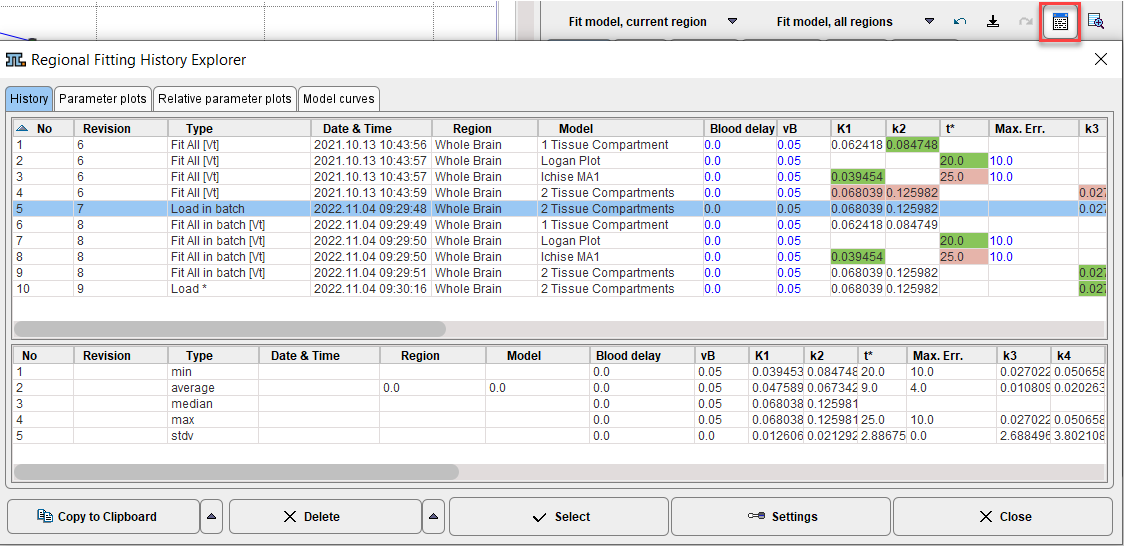
After processing each original data a new file with extended name "batch" is created. It contains in the history all model fits from the batch (as illustrated below), so that a user can simply load the file and step through the fits using the history buttons.
Fitting Options
The Model fit options give access to the mechanisms for improving objectivity and reliability of the results discussed in Fitting Options on Extras Panel with one exception. The First fit blood models option is intended for cases, where interpolation functions are defined for the different blood components but not yet fitted.